I'm building a tool to give LLMs a Lua REPL. My goal is to make it safe by design, so I had to build a sandbox around it. This post is about how I built this, what I learned, and the final result.
What is a sandbox?
Ok, much has been said about how we need to run LLMs/Agents in sandboxes for safety, but what are sandboxes?
Simply put: it's a contained environment where programs being executed only have access to safe operations. Sounds vague? Because it is.
In reality, you can have a sandbox in different layers:
- Operating system: things like firejail, where the sandbox is applied using OS-level isolation primitives (namespaces, seccomp, cgroups)
- VM: you define a boundary by creating a managed runtime that executes bytecode. This extra layer means you can control the execution, since you control the runtime. A prominent modern example is WASM
- Language: the boundary lies in the language runtime. Dangerous library functions are removed from the environment, so untrusted code simply cannot call them.
You then choose the level you want to sandbox by what you are planning to run in it:
- Untrusted binaries? You'll need to secure the OS
- Untrusted modules inside a known runtime? The sandbox usually lies in the VM
- Implementing a plugin system or a DSL? Then the boundary is the language
As you can see, the choice is very natural and derives from the kind of application you are building.
Sandboxing the REPL
To understand where our boundary lies, let's look at where untrusted programs come from:
- From the LLM itself: the idea is to allow LLMs to run code in this Lua REPL, and we know we can't trust LLMs, right?
- Plugins: we want to allow users to define packages to extend what the LLMs can do in the REPL
As we can see, we won't have untrusted native binaries — both the LLM output and user plugins are Lua source code running inside our controlled runtime. So language-level sandboxing is the way to go.
First implementation: block everything
The first implementation was very straightforward: go through the Lua API and block everything that could be dangerous:
pub fn apply(lua: &mlua::Lua) -> mlua::Result<()> {
// First, preserve safe os functions before blocking
sandbox_os_module(lua)?;
let globals = lua.globals();
globals.set("io", mlua::Value::Nil)?;
globals.set("loadstring", mlua::Value::Nil)?;
globals.set("require", mlua::Value::Nil)?;
// And everything else that could be dangerous
// ...
Ok(())
}That's great, and it made everything very safe, but resulted in an almost useless tool. You can still do some math and string processing in this REPL, but can't call any external service, read any file, etc. We need a better way.
Enter policies
One thing I left out of the sandbox explanation is the policy. Basically, for unsafe operations, you define a policy: a piece of logic that judges whether the execution is allowed or not.
The policy can take any number of inputs, and spit out a decision. In rust, it looks something like this:
pub trait Policy {
fn check_access(&self, action: &Action) -> Decision;
}For the current implementation, I decided to go with the simplest approach possible. We define an API spec: a list of functions that are either safe, unsafe, or forbidden. If the function is safe, we allow its execution. If it's unsafe, we pass it through a policy. Forbidden functions are not passed to the policy and are rejected right away, to avoid any policy misconfiguration and reduce the chance of a sandbox escape.
This is a significant improvement over the naive "block-all" implementation. It allows use cases such as:
- Audit: permit but log all unsafe calls
- Dangerous mode: just whitelist everything and trust the LLM - there are crazy people out there
- User confirmation: like agentic coding tools, we can have a policy that prompts an operator to approve/deny the tool call
Demo
To demonstrate the tool and the sandbox policy mechanism, I built an interactive notebook TUI. You can check the code out here. In it, we define an AskUserPolicy that will check with the user whether the execution should be allowed:
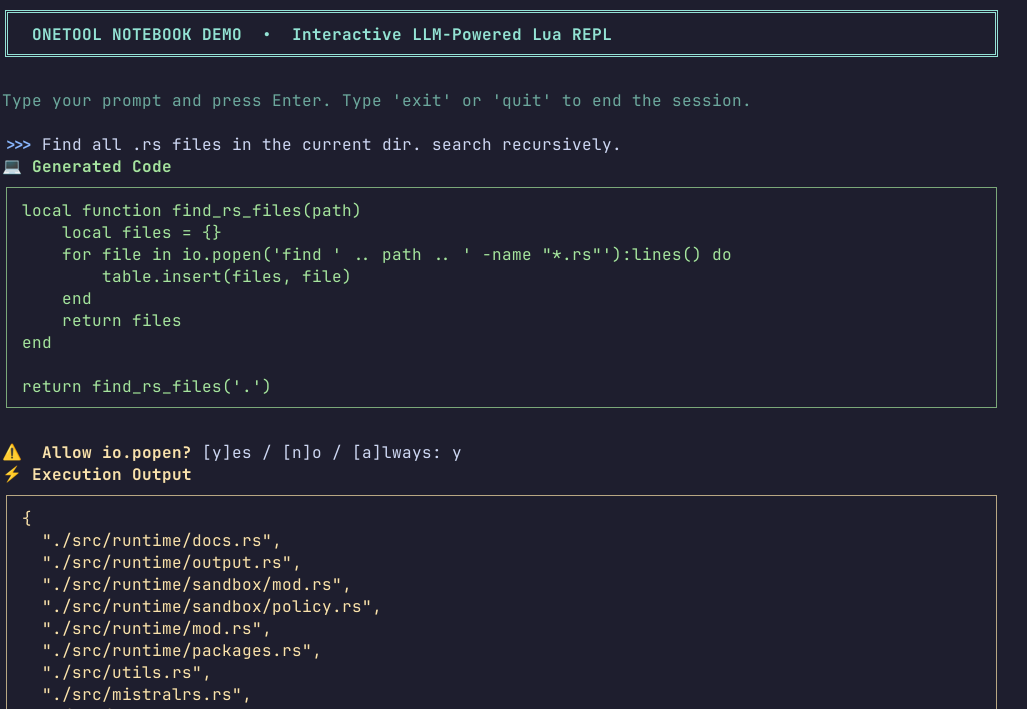
io.popen
Conclusion
This was a fun project. Lua proved once again to be a great foundation for building sandboxed, extensible environments.
That said, there were a lot of things I left out, and might revisit later:
- Memory/CPU limits: depending on your threat model, making sure no code can exhaust the host's memory or CPU cycles is important. From the quick research I did, it is doable
- Take caller into consideration: another cool thing would be to be able to discriminate between code that was written by the LLM, vs code that was imported from a module, but this was surprisingly hard in Lua. There's no reliable way of saying where a function was defined, and every approach I took fell short.
In case you want to check out what I'm building, here's the repo: caioaao/onetool. Also check out the first post I wrote about it, where I go in depth why I'm building this in the first place: Code Execution for LLMs: A Better Approach Than Tool Calls